
Introduction
We recently worked with one of our clients to provide a configuration management capability. This capability assists them with managing the more traditional operating system and application settings in their AWS EC2 environment that run “long lived” applications, or more specifically, those that had lower automation capabilities, or had characteristics that did not lend themselves well to blue/green release methodologies.
As they already had an existing Puppet code base and skill set, they opted to introduce a Puppet Enterprise Master into their environment to handle the configuration and compliance reporting of these particular instances.
Over the last 10 years, Sourced has been involved in a number of Puppet Enterprise deployments and is intimately familiar with the some of the challenges that can come with installing and maintaining Puppet Enterprise. As a result, we set ourselves a number of additional objectives to ensure that the solution was highly performant, resilient to failure, secure and easy to operate.
These objectives were:
- Ensure the solution had the highest levels of automation so that operational overhead was minimal
- Ensure that the solution leveraged an Infrastructure as Code and/or API first approach to deployment and configuration
- Ensure that the solution could seamlessly integrate into the clients existing tool chains; Specifically:
- Datadog for Monitoring
- Splunk for Logging & SIEM
- Atlassian Bitbucket Server for CI/CD & code management
- Ensure that the solution could be easily recovered to a known good state in the event of catastrophic failure of the underlying infrastructure
- Ensure that the solution could be used as a service across the wider AWS environments
- Ensure that the solution was deployed with a high level of security in place:
- Deployed into the client’s private shared services VPCs with no Internet facing interfaces
- Leveraged encryption and strong authentication (for both data, users and systems connecting to the solution)
- Integrated into the group’s single sign-on systems (Active Directory)
- Used a least privilege model for access control (Deploy tokens, RBAC, etc)
In this blog post, we will walk you through how we used AWS OpsWorks CM Puppet to deliver an extremely light, and highly automated, Puppet service in the client’s environment that met all of these objectives. We will also provide some sample code to assist you in implementing it yourself.
Please be aware that this blog post assumes that you are familiar with a number of Puppet Enterprise and AWS concepts.
If you are still learning these technologies, we encourage you look to the excellent learning resources below:
Understanding AWS OpsWorks CM
To quote the OpsWorks for Puppet Enterprise product page:
AWS OpsWorks for Puppet Enterprise is a fully managed configuration management service that hosts Puppet Enterprise, a set of automation tools from Puppet for infrastructure and application management. OpsWorks also maintains your Puppet Master server by automatically patching, updating, and backing up your server. OpsWorks eliminates the need to operate your own configuration management systems or worry about maintaining its infrastructure. OpsWorks gives you access to all of the Puppet Enterprise features, which you manage through the Puppet console. It also works seamlessly with your existing Puppet code.
But what does this really mean and how does this work at a high level?
When you create a OpsWorks CM deployment inside your environment, you are allowing AWS to deploy and manage a set of CloudFormation stacks and its associated resources in your account.
Once deployed, these stacks create a set of AWS resources that includes an EC2 Instance that is pre-configured with a Puppet Enterprise installation running on AWS Linux that is ready for use.
As part of your initial deployment of the managed Puppet solution you have to define:
- A Puppet Enterprise Administrator password
This will enable you to login and configure the various settings for the environment either via the GUI or via Puppet’s APIs. - An SSH Key pair for logging onto the instance
Unlike other managed services in the AWS catalogue, you do have the ability to login to the managed instance. However, we that this only be used for break-glass type actions and that you limit your interaction with the instance to installation of simple agents that may be required for monitoring and logging tasks, and these should also be bootstrapped and managed on the instance itself using Puppet. - A control repository and associated deployment key
Code Manager automates the management and deployment of your Puppet code and Puppet Master configuration from a centralised git repository. When you push code to this repository, webhooks notify Puppet to sync the lastest code to to your masters, so that all your servers start running the new code at the same time, without interrupting agent runs. - An AWS Security Group
This group is used to control access to the Puppet service endpoints within your environment. - A suitable backup window
During this window AWS will create backups of your Puppet instance (containing your deployed code, PuppetDB and other configuration attributes) of which will allow you to recover your environment using the OpsWorks API to a specific point in time. - A suitable maintenance window
During this window, AWS will invoke a set of periodic maintenance tasks for your environment that handles things such as software & operating system upgrades and patches (if / when required).
It is worth noting that when these maintenance tasks occur, the managed Puppet instance is put into a maintenance state. This state also includes a pre-commencement backup that will be used in the event that the maintenance tasks and their canary tests don’t succeed, thus ensuring your Puppet environment is always returned to you in a functional state.
Using OpsWorks CM demonstrates an advanced level of Puppet Enterprise automation that is not often realised by many users and as a result, you are able to spend more time using the product and its capabilities, rather than maintaining it.
In return, after providing these values into the installer, you are returned with a functional Puppet Master endpoint in the *.<region>.opsworks-cm.io domain that you can start using.
OpsWorks AWS VPC Endpoint Configuration
By default, when deploying the OpsWorks Puppet service, it attempts to provision the supporting EC2 instance with a public IP address in a public subnet. Although this is suitable for many users’ needs, in our case, we had a requirement to deploy the instances into a private subnet that had no access to the Internet except via a Proxy service.
As such, we needed to introduce a set of VPC endpoints for a number of different AWS services to ensure that the Puppet Master instance provisioned correctly.
These services are as follows:
- AWS CloudFormation
- EC2
- EC2 Messages
- SSM
- S3
Prior to deploying the service into the client’s accounts, we ensured that these were available. To assist, we have provided some sample CloudFormation code that demonstrates how to implement these in your own accounts and this can be found in the supporting git repository here:
Deploying AWS OpsWorks CM with CloudFormation
Historically, one of the more challenging things when deploying Puppet Enterprise in any environment was the installation and configuration of the software itself. When using OpsWorks, this has been greatly simplified by enabling the provisioning of the Puppet service using AWS CloudFormation.
As a result, a fully managed Puppet Enterprise master can be provisioned in minutes with less than a page of code. Parameters and secrets for the template are sourced from other AWS services such as SSM Parameter store or Secrets Manager.
In the example below, you can see how a fully bootstrapped Puppet Master can be launched using CloudFormation’s AWS::OpsWorksCM::Server resource type.
ProductionPuppet1:
Type: AWS::OpsWorksCM::Server
Properties:
AssociatePublicIpAddress: false
BackupRetentionCount: !Ref BackupRetentionCount
DisableAutomatedBackup: false
Engine: Puppet
EngineAttributes:
- Name: PUPPET_ADMIN_PASSWORD
Value: !Ref AdminPassword
- Name: PUPPET_R10K_REMOTE
Value: !Ref R10KRemote
- Name: PUPPET_R10K_PRIVATE_KEY
Value: !Ref R10KKey
EngineModel: Monolithic
EngineVersion: '2017'
InstanceProfileArn: !GetAtt [InstanceProfile, Arn]
InstanceType: !Ref InstanceType
KeyPair: !Ref KeyPair
PreferredBackupWindow: !Ref PreferredBackupWindow
PreferredMaintenanceWindow: !Ref PreferredMaintenanceWindow
SecurityGroupIds:
- !Ref PuppetMasterSecurityGroupPost Deployment Puppet Automation
Once we have deployed the initial Puppet Infrastructure using CloudFormation, we can then handle all configuration using a Puppet Master bootstrap script.
This script, when run against a Puppet Master endpoint with the Administrator credentials, is responsible for invoking the Puppet services API’s and automatically configuring the following features, resulting in a fully functional Puppet environment without human interaction:
| Puppet Enterprise configuration action | API’s Used |
| Integrate the Puppet Master console into Active Directory allowing single sign-on by support staff immediately | Puppet RBAC API – Directory service endpoints |
| Create a Code Manager User account and associate it with the Code Deployers role automatically Create a Code Manager authentication token for using in CI webhooks and other integrations | Puppet RBAC API – User Endpoints Puppet RBAC API – Token endpoints |
| Trigger Puppet Code Manager to sync all the code from your Git platform to the master and configure all your environments so they are ready for use | Puppet Code manager API – deployment endpoints |
| Using the Puppet Tasks API, Trigger a Puppet run on the Puppet Master itself so its roles and profiles are applied to it, resulting in services such as eyaml, Datadog & Splunk being immediately functional | Puppet Orchestrator – API endpoint Puppet Tasks – API Tasks endpoints |
| Setup the node classifier rules to ensure that nodes that check in are associated with their suitable Puppet Environment | Puppet Node Classification – API endpoint |
When additional configuration changes are to be made to the Puppet infrastructure, they should be implemented here, then deployed to the Puppet Masters automatically.
An example of the bootstrap script output we have developed for our client can be shown below:
# ./puppet-opsworks-bootstrap.sh setup => Checking for the presence of the Puppet Client Tools Package => The Puppet client tools package has been found all OK => Please enter the Puppet Endpoint name (without http://): http://productionpuppet-abcdefg12345i.ap-southeast-2.opsworks-cm.io => Please enter the AD Bind password for the bind account : REDACTED => Please enter the Code Manager account password: REDACTED => Pre-Configuration Confirmation => Endpoint Name: productionpuppet-abcdefg12345i.ap-southeast-2.opsworks-cm.io => Short Name: productionpuppet => Bind Pass: REDACTED => Code Deploy Pass: REDACTED => Do you wish to continue ? (Y/N): Y => Commencing Bootstrap actions => Retreiving the SSL Certificates for the Puppet Service from AWS => Configuring Active Directory Authentication => Creating a deployment user: 'CodeManager' (for Code Manager) and adding to 'Code Deployers' role => Creating access token (CodeManager) and storing in ~/.config/puppetlabs/CodeManager.token => Deploying all Puppet Code manager environments. => Configuring the Puppet Node Classifier node groups => Restarting the Puppet agent on the Master to initiate Puppet agent run and finalise software configuration In approximately 5 minutes the Puppet Master will be ready for use => Puppet software configuration is now complete.
Puppet Master Software Configuration
In the previous step, we automated the configuration of the Puppet software itself. In addition to this, we also need to configure some additional software on the AWS managed instance itself to ensure that it is ready for Production use. In this specific case, we need to configure the monitoring and logging tools the client uses, specifically Datadog and Splunk.
As mentioned previously, when you provision your OpsWorks Puppet Master, it provisions you an endpoint in the *.<region>.opsworks-cm.io domain that you can start using. This value also matches your Puppet Master’s certificate name.
To make this process easy, we use Puppet itself to apply the Splunk and Datadog configuration (profiles) to any instance that checks in with a certificate name that matches our OpsWorks Server naming convention of ^(production|staging)puppet
The implementation logic of this in Puppet code can be seen in the below snippet.
#
# Site.pp - Apply the Opsworks Puppetmaster Role to suitable Opsworks roles
#
node /^(production|staging)puppet.*ap-southeast-2.opsworks-cm.io/ {
include role::opsworks_puppetmaster
}
#
# Class role::opsworks_puppetmaster - Apply the DD and Splunk Profiles
#
class role::opsworks_puppetmaster {
include profile::datadog_agent
include profile::splunk_agent
include profile::puppet_report_hec
}The result of this logic is that when the OpsWorks Puppet server checks into its own environment, it immediately installs and configures the Datadog and Splunk agents on the instance and brings it into service without any human interaction.
Integrating the Puppet Solution into Datadog for Monitoring
When installing the Datadog software on the Puppet Master itself, we opted to use the well maintained datadog_agent module from the Puppet forge which let us easily install and configure the Datadog agent. However, there was one additional task we had to put in place to ensure that the monitoring functioned robustly.
To ensure that Datadog licences were used effectively in the environment, we had to ensure that all EC2 instances that required monitoring had a specific set of tags on them. Failing to do so would have Datadog not make the metrics available. We observed that when the OpsWorks service replaced the Puppet instance during maintenance windows, the tags on the instance were not persisted, and as such the new instance would disappear from the monitoring dashboards.
To address this, we deployed a simple scheduled Lambda into the account that would discover the OpsWorks CM instances and apply the tags if they were found to be absent.
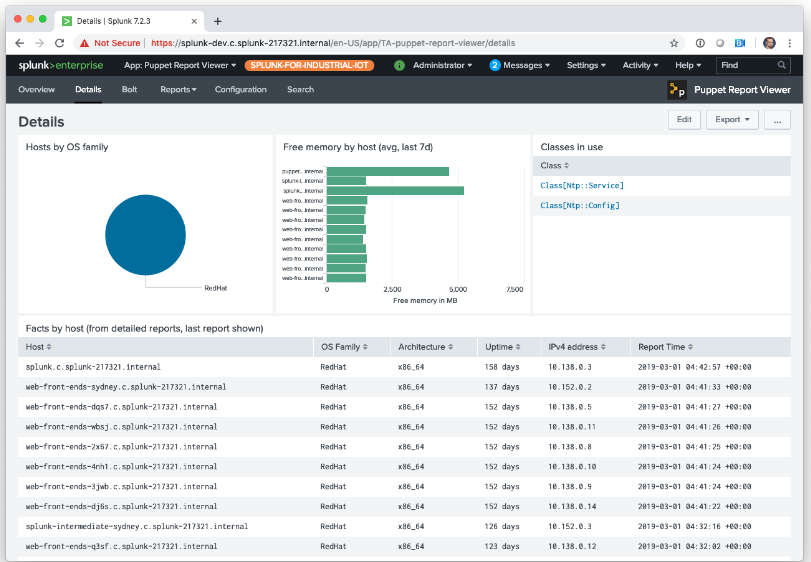
Externalising Puppet Report Data into Splunk for Compliance Visibility
When a Puppet node checks in and completes a Puppet run, it sends a report back to the Puppet Master which details the success or failure of the run alongside a variety of additional information about the resources under management (Files, Services, Users, etc). These reports are then aggregated in Puppet’s internal database (called PuppetDB) where it is used to build reporting dashboards in the Puppet Enterprise Console on the configuration position of your environment.
In this particular environment, for a node to be compliant, it meant that the configuration being applied to an instance is in place and this continues to be the case throughout its lifetime.
As part of the Puppet solution, we wanted to be able to take all the data from the Puppet Master about the success or failures of the Puppet runs into Splunk so that we could combine it with our patching metrics provided from AWS Systems Manager to provide a holistic view on the compliance level for the fleet.
As all this data was stored in PuppetDB, and we didn’t want to constantly poll it to retrieve the information we needed, we introduced the recently released Puppet report processor onto the Puppet Masters that can be found at the URL below:
This report processor functions by parsing the report sent by the Puppet agent to the master at the end of a Puppet run and stripping out a set of core fields which are then passed onto the clients Splunk HTTP Endpoint Collector (HEC), resulting in it being stored in a suitable Splunk index as a JSON string.
As a result of this, we now have a copy of the Puppet report data being sent to Splunk in real time that we can use to build dashboards, providing a deep level of insight into the nodes compliance, especially when combined with other systems data.
This is significantly more effective than having to periodically poll reporting data from the Puppet database itself, and provides us with the additional benefit that the Puppet Database itself on each OpsWorks deployment is no longer critical for reporting needs, resulting in the Puppet Masters themselves being stateless.
Additional Tips
Throughout this project, there were a number of other learnings that we would like to share at a high level:
Avoid unnecessary customisation of the OpsWorks infrastructure
It is important to remember that OpsWorks CM is a managed service, and although you can login and install software on the instance itself, changes to this system may impact the management tasks that are undertaken by AWS to maintain the solution. As such, if you need to install things on the instances yourself, keep it as light as possible and evaluate the potential impact these changes may have.
Only use the Production Puppet environment for OpsWorks agents
By default, the OpsWorks Puppet service is configured to check into the production Puppet environment. It is our recommendation to only use this environment for the OpsWorks nodes, and to not associate any other instances with it.
For all other nodes under management, create suitable environments for them that are separate from the infrastructure and assign the nodes to them accordingly. In doing so, your code release and promotion workflows for the Puppet infrastructure is decoupled from your business units.
Bitbucket Server webhook support
Please be aware that although Puppet Enterprise Code manager is supported with Atlassian Bitbucket Server, the webhook notifications only work with the community webhook plugin payload, and not the native webhook plugins that are now provided in the product itself.
Conclusion
As you can see from the above examples, OpsWorks CM in combination with a small investment in automation can deliver you a highly automated Puppet solution for your environment, allowing your team to get the most out of it without the additional overhead of managing its software stack.
Acknowledgements
I’d like to thank Chris Barker from Puppet and the AWS OpsWorks team for their assistance during this project.
References
- Puppet Report to Splunk HEC Processor
- Puppet @ The Architecture of Open Source Applications
- Puppet Report Viewer @ Splunkbase
- AWS re:Invent 2017: Automate and Scale Configuration Management with AWS OpsWorks (DEV331)
- Splunk – Puppet Report Viewer
- AWS CloudFormation – OpsWorks CM

Keiran Sweet is a Principal Consultant with Sourced Group and is currently based in Sydney, Australia. He works with customers to automate more and integrate with next-generation technologies.


