
We used to joke that engineers only tested software if they lacked confidence in their code. A confident and capable engineer wouldn’t need to write tests at all; their code would always work as expected.
It’s funny because even the best engineer lacks confidence in their code. If we could be 100% confident that code would always function as required, all testing would be wasted effort. But of course, 100% confidence can never be achieved. Even perfectly written code runs in an environment and integrates with systems that can change, uses libraries that can be updated in a way that breaks functionality, or satisfies customer demands that might change in the future.
Testing is unavoidable. Widely used architectural patterns, sophisticated pipeline tooling, hyperscaler cloud environments, the most modern software languages: none of this will produce success without a rigorous and automated software quality practice.
Fully Automated Functional and Non-Functional Testing
A multi-faceted testing strategy yields the best results.
Unit Testing
Unit testing performed by developer at component level, usually during the application development phase.
Integration Testing
Testing that groups two or more modules of an application and tested as a whole. The focus is on interface, communication, and data flow among modules.
End-to-end Testing
Testing in a complete application environment in a situation that mimics real-world use.
Acceptance Testing
Testing application with real time business scenarios. The software is accepted when all features work as expected.
Security Testing
Testing to ensure the application is secure from internal and/or external threats such as malicious programs and viruses.
Performance Testing
Testing to ensure an application’s stability and response time under load.
API Testing
Testing API’s directly to determine if they meet expectations for functionality, reliability, performance, and security.
Compatibility Testing
Testing which validates how software behaves and runs in a different environment. Important when migrating to new technology or tech stack.
This article discusses the characteristics of a successful quality practice and how we’ve built a testing framework around open source tooling to embed quality into clients’ software.
Good vs Bad Testing
Good Testing
Good testing seeks to achieve the following goals:
- Emphasise automation. The quality of manual testing is dependent on the tester and how well they are performing on any given day. Automated tests execute quickly with consistent and reliable quality, and can be run in parallel.
- Promote rapid deployments — reduce lead time to deploy changes. This can be accomplished by replacing slower manual testing with more rapid automated testing. If used appropriately, the framework should reduce time code spends in a build pipeline. This reduces work-in-progress (WIP) and promotes frequent small deployments, a practice which results in safer and higher quality releases than infrequent large deployments.
- Facilitate parallel testing. It is important to run tests in parallel, rather than sequentially, to reduce time spent testing and accelerate delivery of features to customers.
- Improve quality and reliability of software. Enhance the quality and reliability of software releases through consistent application of testing standards in an automated way.
- Reduce WIP. Automated testing completes much faster than manual testing. This means code can get through a pipeline faster. The total WIP for a team is reduced and effectiveness increases.
- Use intuitive, easy-to-use tooling. We often work with clients who are replacing manual testing with automated testing. Their manual testers frequently lack technical skills but do have deep, intuitive knowledge of how a system behaves. An effective testing framework takes advantage of manual testers’ application knowledge by providing a natural language framework for them to write robust and reusable automated tests without knowing the specifics of any particular programming language.
- Test early and often. Encourage ‘shifting-left’ on testing, so engineers can run tests against code in development before making a pull request or committing to a repository.
- Be application-agnostic and work across all API-based applications. This means the same number and types of tests (API, Integration Acceptance, Performance, and Compatibility) can be generated against a variety of different applications.
- Provide immediate feedback on failed tests. Which test(s) failed and any error codes or messages provided by the application are critical pieces of information. This feedback should be provided whether the tests are run on an engineer’s laptop or as part of a DevOps pipeline.
- Provide the capability to designate any test failure as a blocker or non-blocker for deployment of the build. These settings should be context specific, meaning they could differ depending on whether the test is run on a personal laptop, as part of a DevOps pipeline, or some other situation.
- Provide for flexible test execution. Individual tests and entire test suites can be launched automatically as part of a build pipeline or manually from an engineer’s command line tool or development environment.
- Tests are storable, repeatable and can be run at will.
Bad Testing
The easy and true answer is to say bad testing is the opposite of what is listed above, but it is worth emphasising a few key characteristics of bad testing:
- Manual. Repetitive manual work soon becomes tedious, and work that is tedious soon becomes error-prone. Little in software is more tedious and error-prone than manual testing. This manifests itself in both missed defects and erroneously reported defects. A team’s WIP increases because testing can take weeks while engineers continue to write code and deliver features.
- Slow. Slow testing has repercussions that reverberate throughout a deployment pipeline (see ‘The Large Deployment Death Spiral’ described below).
- Inconsistent, not repeatable. Errors in testing kill productivity. In this case false defects can sometimes be as bad as missed defects.
- Failing to test the entire system. This is a characteristic of slow manual testing and often happens as a result of time pressure. There is not enough time to test everything so only the most recently changed or most important features are tested. A team might be able to get away with this for a while, but in the end undetected errors come back to haunt them. When a production error is discovered it can be very awkward to explain “we didn’t test that because we didn’t have time”.
‘Shifting Left’: Test Early and Often
Think of the development cycle as a line running from left to right. At the far left of that line is when code is written. Towards the right is when that code is deployed to a test environment. At the very right end of that line is when code is deployed to production.

In a typical waterfall software development project testing occurs after deployment to a test environment and immediately prior to release into production. Maybe some testing is also done in production after deployment, but the focus is on testing in the test environment.
If defects are found in the test environment the entire release is delayed until the issues are resolved and re-validated. Of course, in the meantime engineers keep writing code. The next deployment tends to be even larger, more complex, and more likely to fail than the last. This leads to the deployment death spiral detailed below.

Shifting left on testing means testing towards the left end of that line — early in the software development process. The goal is to find defects as close in time to when they are created as possible. Testing is done ‘early and often’ throughout the development process as opposed to all at once when code is deployed to a test environment.
It is hard to overstate the benefits of shifting left. This practice allows defects to be found early in the process, often on an engineer’s local machine before code is even deployed to a test environment. The engineer can quickly implement a fix and there is no need to enter and track a defect report or wait for deployments to a test environment to validate the fix.
Even better, finding and fixing defects close to the time they are introduced avoids further code being layered on top of the erroneous code. When this happens, it tends to increase the difficulty of fixing the original defect as well as introducing additional defects on top of it.
Shifting left on testing provides other critical benefits:
- Finding bugs early in the software development life cycle reduces the cost of fixing them.
- Higher-quality products because fewer patches and fixes are required.
- Increased probability that the product will meet estimated delivery timelines.
- Maintaining a higher-quality codebase.
Getting it Wrong: The Large Deployment Death Spiral

Slow, incomplete or erroneous testing can have an outsized impact on an engineering team and a build pipeline. The following pattern is common in the industry:
- Testing is done manually. To fully test an application can take several weeks even if the changes or defect fixes are small in scope. As testing takes longer and longer, more features are added to a product, increasing WIP.
- As a result, the number of production deployments per quarter decreases. Since engineers continue to write code regardless of how frequently it is deployed, the size of each deployment grows correspondingly. Both the time and difficulty to test increase as do the odds that a defect will be released into production.
- With more code and more defects released with each production deployment, the percentage resulting in customer complaints and emergency hot fixes increases.
- Because the amount of code released in each production deployment increases the time to investigate, fix and test production defects also increases.
- The increase in production defects prompts management to increase the amount of time spent on testing, most often initiating additional manual testing ‘just to be sure’ the automated tests are running correctly. This further slows the deployment rate, increases the amount of code in each deployment, increases the odds of a production defect, and increases the time to fix that defect.
This becomes a downward spiral. Dissatisfied customers don’t understand why your software can’t be made to work properly. They are aggravated by wasted time, expense, and overall poor quality. Your customers are likely to switch to other providers if given the chance.
Software Quality: The Overlooked Pillar
Four Pillars of Application Modernisation
Enhancing Core Capabilities
Cloud-Native Application Platform
- Self Service Platform mentality
- Everything as Code
- DevSecOps pipelines
- Optimized Kubernetes clusters & serverless solutions
- Service meshes implementations
Cloud-Native Application Refactoring
- Decoupled architectures through Domain modeling
- Microservices acceleration
- Application refactoring to leverage native cloud technologies
- GraphQL at Scale
- Serverless at Scale
Application Quality & Security
- Shift-left continuous testing
- Automated Unit, integration, functional, end to end testing strategy
- Release process re-engineering with B/G/Canary
- Continuous Delivery
Data Modernisation
- Migration off expensive legacy data solutions
- Re-designing for the right storage solution
- Decoupling data by Domain for microservice solutions
- Data mesh design& implementation
Developer Experience
Above shows four pillars to successful application modernisation efforts. All are necessary for a successful application modernisation, and none can be skipped.
In our experience, the pillar most likely to be overlooked is Application Quality and Security. A team can only achieve so much without rigorous automation testing. It is very important to build highly optimised Kubernetes clusters that house well-designed microservices all working in highly optimised cloud environments. However, even with these advantages a team will fall short if code takes weeks to get through testing and test quality is poor. Slow deployment frequency results in increased deployment size and high WIP. More defects find their way into production resulting in more re-deployments which further increases the size of future deployments — and the cycle continues.
Sourced Test Framework Overview
Application Testing
What does a successful testing protocol look like?
An efficient and comprehensive testing strategy is essential to team success. Without rigorous and efficient testing optimal cloud landing zones, great decoupled modern architectures and zero-touch DevSecOps piplelines and practices will be wasted.
Test Early and Often
Fully automated platform runs repeatedly with no human intervention.
Shift-left
Enable testing as early in the development process as possible, before filing a pull request.
Observable
Easily identify which tests failed and where the failure was.
Extensible
Use the same platform and same techniques to test multiple applications.
The purpose of this blog is to describe the rationale and architectural design of our Karate-based Framework. We cover:
- An overview of the high-level architecture as well as the breakdown of internal subsystems.
- How the framework promotes standardised testing practices, reduces lead time to deploy changes, and promotes shifting left on testing.
- A description of technologies used throughout the framework.
- The benefits of implementing a single test framework and test practices across engineering teams and groups.
Framework Design Goals

Expand QA Range and Capabilities
When we introduce test automation to an organisation we’re often asked: “How do our manual testers fit into this new system? They don’t know how to code.”
The answer is that our framework can be used by staff with a broad range of engineering skills, including those with no engineering skills at all. It’s based on Karate and Cucumber technologies: tests are written using Karate DSL which is based on the intuitive Gherkin language. After a short training period, formerly manual-only testers can become productive writing automated tests.
The framework also promotes secure practices by:
- Adhering to the security standards used by the application tested in terms of HTTPS/TLS encryption, JSON Web Tokens, RSA keys, etc.
- Employing test users with varying degrees of security permissions.
- Testing APIs directly and through HTML clients.
Karate
Karate DSL, based on the Gherkin language used in the Cucumber testing tool, is used to automate testing of REST APIs. The DSL is based on natural language and allows staff with and without engineering backgrounds to productively create automated tests.
Best practice dictates that tests are written as APIs are developed. This approach not only results in higher quality code but supports shifting left, whereby automated testing is done earlier and earlier in the development process, ultimately on a developer’s laptop before a pull request is made.
Building on Karate Framework Capabilities
Karate is an open source test framework and Karate tests are described using the language neutral behaviour driven development (BDD) syntax popularised by Cucumber. The syntax is easily understood by non-programmers or novice automation testers.
Karate itself is written in Java and can be invoked from any build tool using pom.xml. It also integrates with third party reporting and load testing tools designed for DevOps and continuous integration. What’s more, it provides users with the ability to execute test cases in parallel and validates JSON and XML.
Our framework is built on top of Karate and has the following capabilities:
- API test automation
- Mocks
- Performance-testing
- UI automation for certain clients (not Android)
- Non-coders can use language-neutral Gherkin syntax developed by the Cucumber test framework. There is no compile step to Gherkin test scripts.
- A Java API (https://karatelabs.github.io/karate/#java-api)
- Built-in HTML reports.
- Parallel running of tests
- Performance testing through integration with the Gatling framework
The framework can be used to help automate the following types of testing:
- Testing as part of CI/CD pipeline. Automated tests should be committed with code changes and be used to validate functionality. Shift left practices can be employed to validate the tests by running them on a developer’s laptop against the code to be tested, before a pull request is made.
- Contract testing. Testing to make sure that services can communicate with each other and that the data shared between the services is consistent with a specified set of rules.
- Performance testing. Non-functional testing that measures the speed, stability, scalability, and responsiveness of an application under load.
- Load testing. Measures how well an application performs under real-world scenarios where a high number of calls are made or large amounts of data are transferred.
- End-to-End testing. Tests an application’s workflow from beginning to end, replicating real user scenarios so the system can be validated for integration and data integrity.
- Chaos testing. Involves purposefully crashing, or making unusable, various components of a system and assessing how the remaining system responds. The goal is to gather information that helps reduce the mean time to recovery (MTTR) after a failure.
High-Level Architectural Overview

Component Descriptions
pom.xml
A Project Object Model or POM file is the fundamental unit of work in the Maven build tool. It is an XML file that contains information about the project and configuration.
Karate
While Karate tests are defined using BDD syntax, Karate itself is written in Java and it is invoked from Maven using pom.xml.
Karate Runner Class
This is a core Karate feature. The framework base runner class contains the core project which has all the logger and reporting methods.
Some of the functionalities of the runner class are:
- Choose features and tags to run and compose test suites.
- Runner returns a Result object, which can be checked to see if any scenarios failed and to summarise errors.
- Suppress parallel execution with the tag @parallel=false:
- If the tag is placed above the Feature keyword it will apply to all scenarios.
- If the tag is placed above a scenario just that scenario will not be run in parallel.
For example:
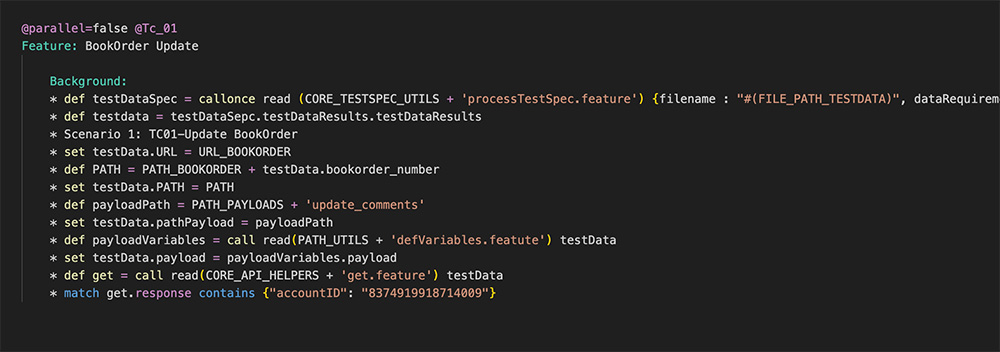
Karate Config
Karate expects a file called karate-config.js to exist in the classpath. This file holds all the configuration information. A javascript function in Karate-config is called by default and returns a JSON object. The keys and values in that JSON object are available as script variables, specifically endpoints path, service path and environment variables.
Karate Test Features
Karate references Cucumber test definitions as ‘*.feature’ files.
The Karate test package contains all the test case files. It is recommended that tests be organised in sub folders by service or functionality.
Karate Mock Features
Karate *.feature files may also define mock services.
Mock Responses
Karate mock features may reuse JSON response files created for unit tests if possible. Otherwise specific mocks built for integration tests may be used.
Microservice Under Test
Target of the current test.
Microservice Config
The microservice config will reference mocks instead of the actual dependent services during integration testing.
Mock Dependent Services
Each dependent service referenced by the microservice under test will be mocked during integration testing.
Framework Features
The Framework also provides these additional features:
- Karate DSL enables writing quasi-English test scenarios.
- Scenarios may be reused or run in parallel.
- Test scripts in Gherkin or Java
- Built-in reporting
- Independent test data and scripts
- Flexible test data storage
- Performance testing via Gatling
- CI/CD pipeline integration
- Test script management via repository
- Ability to save time by concurrently running different tests
These capabilities are described further in the sections below.
Test Scripting in Gherkin or Java
The framework is built on top of Karate and Cucumber, with tests typically written in Gherkin syntax although Java may be used. Staff with no or limited engineering experience often write tests in Gherkin, while more experienced engineering staff may write tests or supporting features in Java.
Built-In Reporting
Reports are generated automatically simply by running tests themselves. JUnit runner is used for the execution of different scenarios included in feature files and JUnit automatically creates a report in both cucumber.html and custom-extend-report for each feature file.
Most CI tools, such as Jenkins, are compatible with the Cucumber HTML report. The report can be generated as part of the build pipeline.
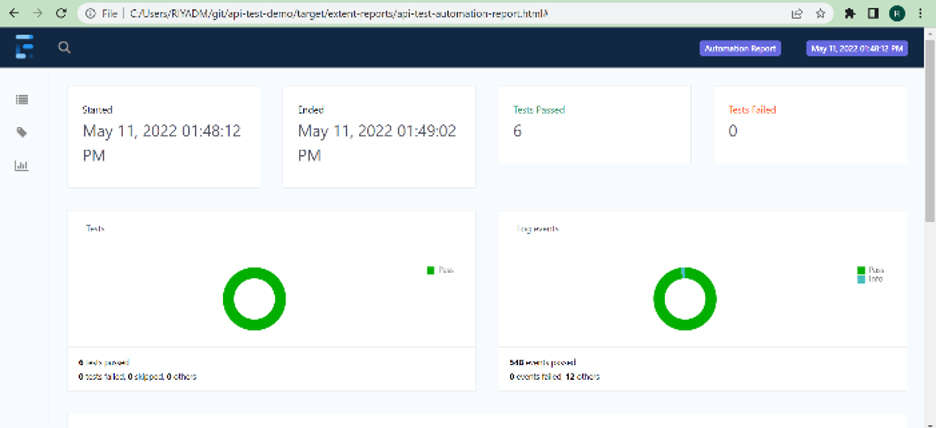
Independent Test Data and Scripts
A request payload is data that clients send to the server in the body of an HTTP POST, PUT, or PATCH message. The payload contains important information about the request.
It is good practice for request payloads to be kept separate from test cases in a datastore (database, S3 bucket, file system, etc).
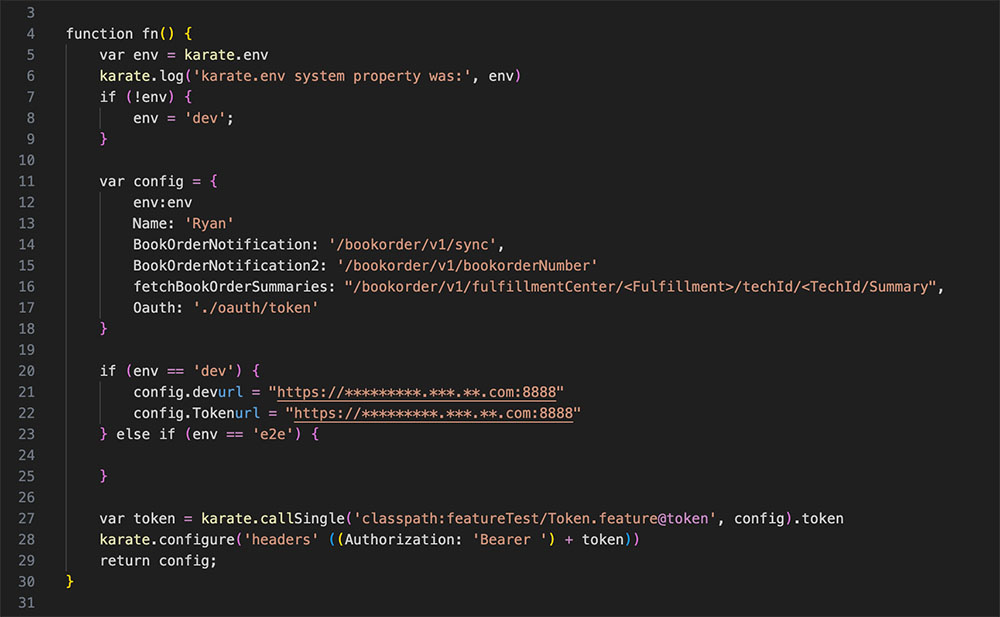
Performance Testing via Gatling
The framework provides integration with the Gatling performance testing tool. This allows testers to run performance tests using the same features and scenarios used in other forms of testing.
Gatling capabilities include:
- Reuse of framework tests as performance tests executed by Gatling.
- Framework assertion failures appear in Gatling report, along with the line numbers that failed.
- Assertion capabilities check that server responses are as expected under load.
- Scaled testing via distributing execution over multiple hardware nodes or Docker containers.
CI/CD Pipeline Integration
Framework tests can be integrated with widely used pipeline tools, such as Jenkins, Gitlab, CircleCI and others.
Ability to Run Parallel Tests
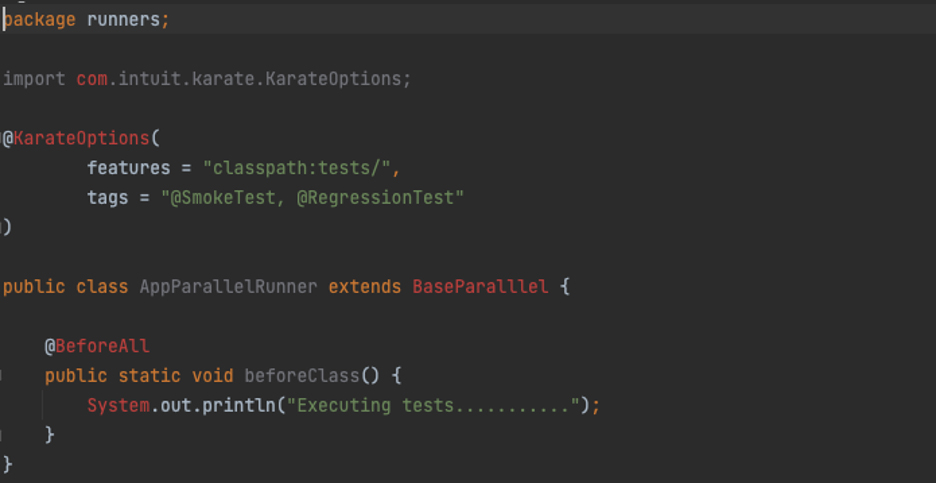
One of the key metrics used in DevOps is ‘lead time for changes’, which means the clock time from when a pull request is approved to when the code change is deployed to production.
Automated tests generally run faster than manual tests, but can still take substantial clock time if run in sequence.
To further reduce lead time for changes the framework can run tests in parallel. This dramatically reduces clock time spent testing. The screen shot above shows the AppParallelRunner class which implements parallel running of tests.
Other Framework Features
The framework also provides many other features, including:
- Embedded regular expression and JS engine support.
- In-line HTTP logs.
- Easy debugging using Karate UI.
- JSON schema validation support.
- Integration with JUnit and TestNG.
- Reusable function and feature files.
Dependencies & Tooling
The primary framework prerequisites are:
- Eclipse IDE, IntelliJ or VSCode are recommended but not required.
- Java / JDK 8.
- Maven or Gradle.
- Karate-junit5 Dependency.
Manual testing is time-consuming. For every large or small production deployment testers must manually repeat a set of test cases to ensure a defect has been fixed, a new feature has been correctly added, and also that no new defects have been introduced. Regression testing has been a time-consuming pain point for developers and testers. In the case of manual testing, a release can take up to three weeks; this can be reduced to under a week with the help of automation.
Automated testing is a faster, more efficient option when it comes to almost any testing. Time is invested once in building an automated test case. A similar amount of time would have to be invested manually testing each release.

Summary
Without effective software quality practices most application modernisation efforts will fail. Even quality practices that are otherwise effective tend to result in the Large Deployment Death Cycle, and eventual failure, if they are too slow.
To avoid failure it is important that key portions of the engineering and quality process are standardised and automated. This way:
- As engineers move from team to team they can use familiar tooling and practices and maintain a high velocity.
- Innovations created by any one team can be shared across the organisation. In this way all teams can improve more rapidly.
- An organisation-wide standard practice is more likely to be followed than ad-hoc practices created by individual teams.
Using the framework across teams and groups is an effective way to promote standardised testing practices and results across the organisation.
Build Software that Thrives on Change
It is not the strongest of the species that survives, nor the most intelligent that survives it. It is most adaptable to change.
Charles Darwin
In our experience engineering organisations can be broken down into three groups:
Base-level engineering organisations employ many manual processes. Performance declines rapidly under a limited amount of change or load. Their capacity for improvement is small and they can only recover to baseline performance with extreme difficulty.
Effective engineering organisations produce good quality software while enduring a moderate amount of change or load. If either exceeds a certain threshold, performance rapidly declines. These organisations use some automated processes while still depending on manual work for important tasks. Their capacity for improvement is modest and they can recover to baseline performance with moderate difficulty.
Elite engineering organisations grow stronger as more change or load is applied to them, in the same way the human body grows stronger through rigorous exercise. They actively seek to learn from mistakes and incorporate those learnings into future work, often embracing cloud infrastructure and cloud-native architectures. These organisations depend heavily on automation to increase quality while reducing cognitive load on teams and individuals. Their capacity for improvement is great and they can recover to baseline performance with relative ease.
Implementing effective quality practices is just one step on the path to elite status.
Appendix: Useful Links & Reference Material

Mike is a Managing Principal Consultant at Sourced Group. Over the last 25 years Mike has worked as an engineer, architect, and leader of large engineering organizations.

Scott is the Head of Consulting for the US at Sourced Group, with over 17+ years of experience. He has designed, built, and managed extensive customer-facing programs across the public cloud engineering stack. In his 7 years at Sourced, Scott has developed cutting-edge, cloud-native solutions for some of the US' largest customers.


