Background
Data Governance is often on top of the Chief Data Officer’s agenda. With the advent of the General Data Protection Regulation (GDPR) in Europe, the California Consumer Privacy Act (CCPA), the China Personal Information Protection Law (CPIPL) and others, companies are taking a closer look at their data practices.
Beyond the need for regulatory compliance, our clients are voicing others concerns, such as:
- “Data governance is important; We need to make sure our data access and data manipulation is transparent on-premises and in the cloud.”
- “We have challenges with our business intelligence capabilities: our consumers question the data they see. We need to trace back the data source and the steps the information went through (data lineage).”
- “We don’t know how to prove the regulator that our threat model is sufficient to protect the services running on the cloud, which access to our data”.
Can we have a pragmatic approach to this vast subject when it has so many different meanings to people? Are we talking about data security, data ownership, data life cycle management, transparency and control, or just all of the above?
How do we address data governance in highly regulated industries such as financial services, translating the regulations into the public cloud realm?
Do you have similar concerns? If these questions resonate with you, do read on.
Cloud Challenges and Opportunities
When moving data to the cloud, many of the on-premises data requirements remain, such as:
- Data protection,
- Secure data access,
- Authorization / entitlement enforcement.
As our clients are moving their centralized data platform to the cloud, they face new challenges :
- How to implement complex cross borders compliance requirements across each cloud geography defined by the Cloud Services Providers
- How to address data sovereignty, which might prevent the use of a global data platform across geographies, since data movements are restricted by the countries’ regulators
- How to implement data lineage across multiple data platforms if it’s not possible to have one global data platform
- How to address data observability across regions to provide visibility of all operations performed on data
At the same time, by adopting cloud technologies, users get the benefit of maximising business insights, thanks to:
- Ease of data acquisition
There is a plethora of tools from the Cloud Services Providers that help clients collecting data from on-premises and store it into an optimized format (e.g. columnar format such as Parquet or other) on the cloud. - Discovery capabilities to experiment more often
Data catalogues’ functionalities are built-in and provide an instant view of the latest data that has been brought into the cloud storage. - Faster access to data
With security controls built into the cloud services (there is no additional layer to be built to protect data access on top of each data pipeline for example), providing data access through one of the data services can be faster than accessing on-premises data. - Flexibility in manipulating the data
Interactive query tools don’t require any software installation or complex configuration. They are ready to be used. - Seamless and flexible access to the tooling
Data engineering & data science workbenches have native access to data and can be instantiated in a few clicks.
Can we adapt the existing data processes that have been designed for on-premises environment, in order to address these new challenges while taking advantage of these benefits?
To do so, while simplifying the data journey of our clients, from on-premises to the cloud, we suggest the four-steps approach, which we use commonly at Sourced Group:
- Design a Data Security & Control Framework
- Standardize Data Pipelines with three stages of data transformation
- Design Data Sovereignty & Compliance in all data movement
- Define the Data Migration Blueprint
This approach helps our clients addressing their new compliance requirements and meeting their users’ expectations. The four steps are detailed hereafter.
Design a Data Security and Control Framework
To address data protection, secure data access, and authorization / entitlement requirements, we recommend a holistic approach that takes into account the three data classifications:
1) Confidentiality, 2) Availability and 3) Integrity, named sometimes as “Business Impact Analysis” (BIA)
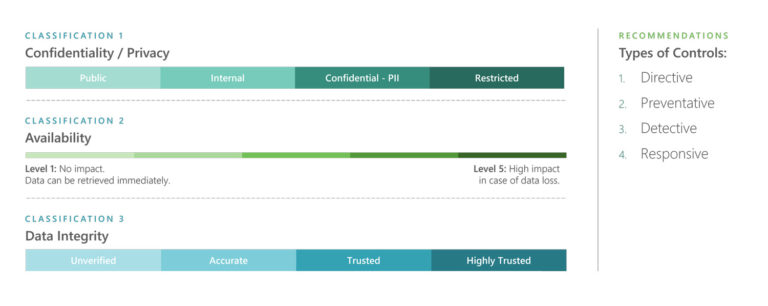
The Business Impact Analysis (BIA) rating drives:
- The data protection pattern:
- This includes encryption, and a combination of masking & tokenisation.
- The number of service controls associated across four categories of controls:
- Directive controls
- Preventative controls
- Detective controls
- Responsive controls.
This approach guarantees the data security with the right level of protection & control based on its classification, by design. To dive deeper on data protection, I recommend that you read the Blog posts from my excellent colleague at Sourced Group, Thomas Smart:
- Personally Identifiable Information in Regulated Organisations
- Protecting Personal Data in Serverless Cloud
The data and control frameworks are built into the Automated Data Platform Infrastructure and integrated in the Data On-boarding Engine (see last section – ‘Resulting Data Platform’).
Standardize Data Pipelines
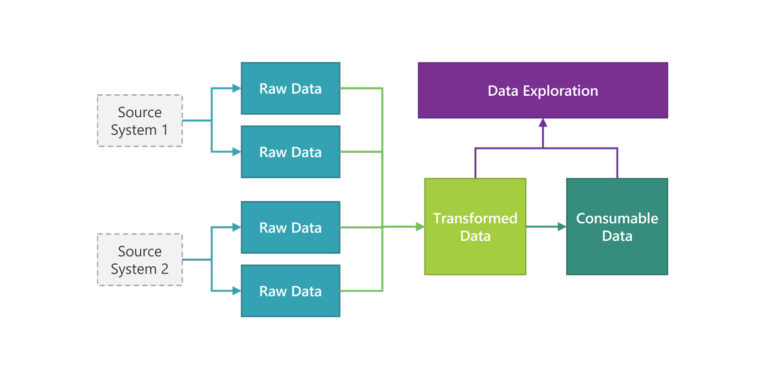
In a typical Data Analytics Platform, we recommend to define three stages of data:
- Raw Data: data is captured from the source systems (transaction applications) and protected according to the Business Impact Analysis rating of, either each dataset, or each data field within the dataset. Then, data is made available on the Data Analytics Platform on the public cloud. This raw data is the golden source for the running Data Pipelines on the Data Analytics Platform and is ringfenced to prevent any alteration. The original copy is kept on the Data Analytics Platform and a copy is archived using the cloud service provider lifecycle policies.
- Transformed Data: raw data that has been standardized, cleaned and recorded in a Unifed Metadata Store / Data Catalogue with its specific domain and sub-domain. This data can be further agregated within its transformed stage.
- Consumable Data: this end state of the data is consumable by a data warehouse, an application using an API, or a Machine Learning pipeline to train a machine learning model.
The diagram below depicts the three stages of the data, before they can be consumed. The definition of the three data stages enables exploratory analysis on transformed and consumable data using cloud native and serverless technologies.
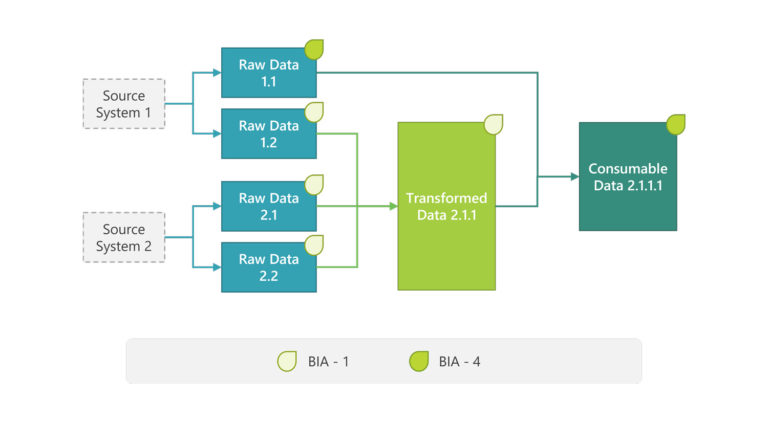
Each dataset has an associated BIA rating that is carried within a data contract. This data contract is a policy document that follows each dataset through its transformation journey: from Raw Data, to Transformed Data and then Consumable Data.
For example in figure 3 below, the consumable data 2.1.1.1 is formed by combining raw data 1.1 and transformed data 2.1.1. The final consumable data also inherits the highest security classification of its constituent datasets:
With the definition of standardized data pipeline and the associated data protection accomplished, we can now add the data sovereignty and compliance into the picture, with a simple mapping to the three stages of data transformation.
Design Data Sovereignty & Compliance In All Data Movements
To address complex cross borders compliance requirements across geographies, we integrate data sovereignty requirements in all data movements in the public cloud.
An application hosted on-premises might serve multiple geographies such as China, Hong Kong, Australia, Singapore, etc…, But moving the application and/or the underlying data to the cloud requires to comply with more recent data sovereignty rules, which differ from country to country.
Our clients often use the concept of market instead of country. A market corresponds to a specific geography (country) or a set of countries (example: Central Europe) where rules from a single regulator apply. At Sourced Group, we have taken this market approach to the cloud and defined the Cloud Market Access Layers.
The Cloud Market Access Layers is a conceptual cloud regulation model that we introduce to assess cloud regulations across 3 layers: data persistence, data processing, and data consumption. It serves as a framework to determine cloud resources deployment patterns on different regulation scenarios. The concept is best illustrated with the following diagram:
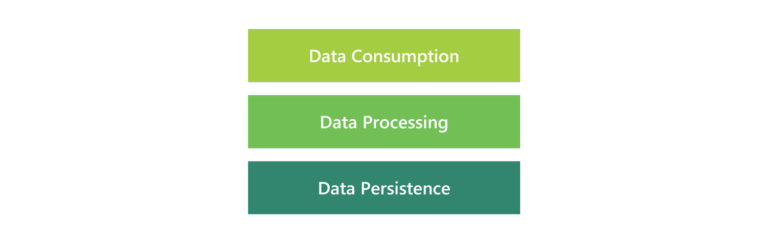
Data Persistence / Sovereignty is the primary layer, where regulations are imposed on data movement to meet the relevant compliance requirements. Some country regulators impose that personalized identified data can’t move out of the country jurisdiction. Data has to persist in the region it was produced.
Data Processing can be allowed by regulators outside the region in which the data persists. This implies that data consumption is also allowed outside the region the data persists. To generalize these subtle differences, we recommend coupling the processing layer to the data persistence layer, thus making data processing happen in the same region where data must persist. In these cases, this translates to Restricted Market, which is described later in this section.
Data Consumption: regulations might dictate where the data should be consumed from. In most cases, local consumption is the default. However, some use cases require the data consumption to be done outside the local region as well.
For example: within a corporate banking business, an enterprise relationship manager sitting in Singapore may want to look at the transactions of all the subsidiaries of his client (a large company) across APAC. This implies that transaction details of the subsidiaries (Indonesia, China, India etc…) will be consumed in Singapore, outside the region where the data is stored in the cloud.
This Cloud Market Access Layers approach drives the architecture design patterns that cater for different regulation scenarios, which leads the concept of “Cloud Market”. We have identified three types of Cloud Markets prevalent for our clients in financial services:
- No Cloud Market: itemized clients data are not allowed to move to the cloud
- Restricted Cloud Markets: data need to be stored and processed within the country. This can require a specific cloud provider (Ex: Indonesia, China, India)
- Global Markets: clients data can be stored and processed on the cloud, in a cloud region outside the country.
The data movement from on-premises to the two cloud market types is illustrated below:
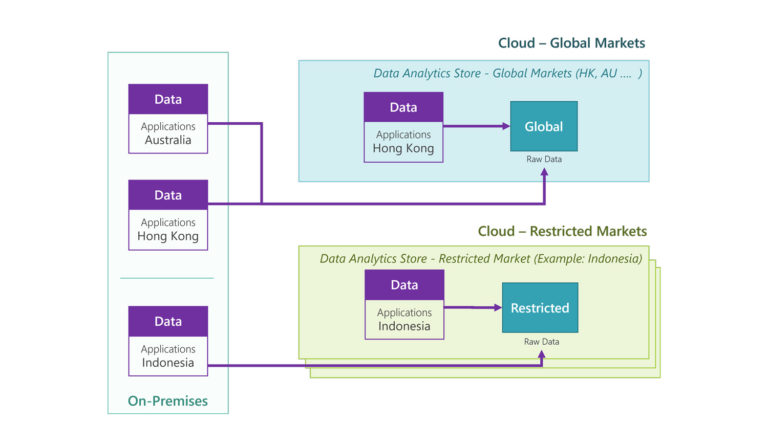
In a given deployment, we expect to have:
- One Data Platform to serve a global market
- One Data Platform in each restricted market.
Let’s add the standardised data pipeline dimension (three stages of data) to the data sovereignty: together, these dimensions constitute the Data Migration Blueprint described hereafter.
Data Migration Blueprint
The diagram below combines the three stages of the data (Raw, Transformed and Consumable data), with the three layers of data sovereignty. It depicts the data migration path to a set of Restricted Cloud Markets, and to one Global Cloud Market, depending on the public cloud regulations that are countries specific:
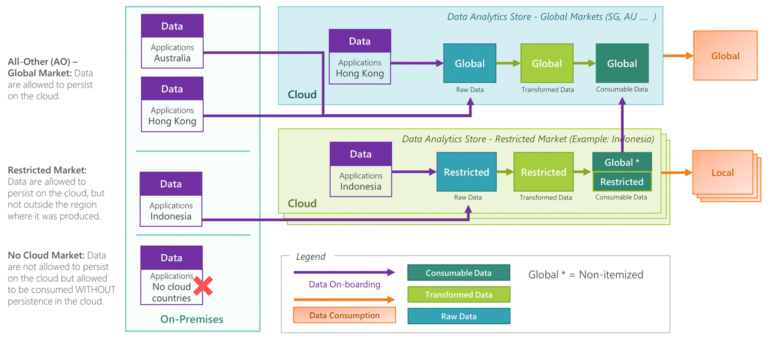
In the data migration path described above, within a restricted market (light green rectangles), we can optionally sub-divide the consumable into two categories: “restricted” consumable data and “global” consumable data (within the dark green rectangle). This “global” consumable data is a subset of the consumable data within a restricted market: It do not contain itemized data and can be moved across regions. This allows global applications to collect (non-itemized) data from the restricted markets and to provide a holistic view, for example, to a bank relationship manager, who oversees the transactions of a corporate client across multiple geographies.
Up to this point, we have defined the data governance of the Data Platform. Let’s now add the functionalities that will support these data governance requirements and put together the resulting Data Platform.
Resulting Data Platform
The resulting Data Platform is a template / blueprint that we replicate across the two cloud market types: one global market and a set of restricted markets.
The data platform blueprint implements the data migration design explained above and is made up of two components: a Platform Automation containing the automated provisioning of analytics infrastructure and the Data Management layer, which contain the data infrastructure applications:
- Platform automation
- Automated Data Analytics & ML tools provisioning to perform data analysis and data science in a controlled and self-service environment:
- Direct data query
- Dashboard building
- ML Ops environment.
- Automated Data Analytics & ML tools provisioning to perform data analysis and data science in a controlled and self-service environment:
- Data Management layer
- Data On-boarding engine with built-in security & data protection
- Data Catalogue to discover what is out there, and what users are entitled to
- Flexible entitlement layer with a combination of tags-based access control and role bases access control.
- Schema with tags associated to each dataset (Data contracts)
- Authorization tags associated to the users: geography etc…
Here is the resulting data platform, which is deployed in the global market:
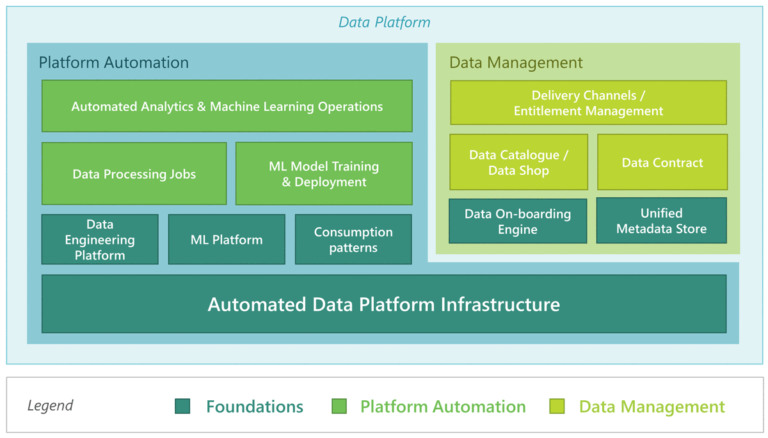
In a restricted market, the resulting data platform inherits some of the functionalities from the global market such as Unified Metadata Store and Data Catalogue. Other functionalities like “Delivery Channels / Entitlement Management” will be market independent and run in the global market.
At Sourced Group, we simplify the deployment of these two data platform types by having a common analytics infrastructure base (Platform Automation in Figure 7) and a differentiated Data Management layer.
With built-in security, services controls, and a dual market concept, we have a robust pattern to address the data protection & compliance challenges, while delivering on users’ requirements:
- Ease of data acquisition
- Discovery capabilities to experiment more often
- Faster access to data
- Flexibility in manipulating the data
- Seamless and flexible access to the tooling
References & Acknowledgements
- Designing Data Platform on the Cloud, co-authored by Danil Zburivsky (Senior Consultant at Sourced Group)
- Personally Identifiable Information in Regulated Organisations
- Protecting Personal Data in Serverless Cloud
Thanks to Som Kapoor (Senior Consultant, Security), Johann Thum (Consultant, Data Analytics) and Zhong Hao Neo (Machine Learning Engineer), Danil Zburivsky and Farshad Ghodsian who provided their expertise and contributed to this blog.
Interested in diving deeper into how our clients took advantage of this approach?
Let’s Connect
Jean-Michel Coeur is a Principal Consultant and the Head of Data Practice at Sourced, having served clients during more than 30 years. With his extensive experience working backwards from clients’ requirements in a variety of industries (Financial Services Industry, Manufacturing, Energy, Travel & Telecom), Jean-Michel has led engagements and accelerated cloud adoption at more than 30 enterprise clients across ASEAN in the last 5 years. This helped them change the way they go to market and serve their clients, using advanced analytics & machine learning technologies on the cloud.


