
Introduction
With recent advancements and the on-going adoption of immutable infrastructure, it has never been easier to deploy and maintain highly scaled applications in the cloud. If your system requires an update, you can simply make your changes in code and re-deploy the resources. While the immutable approach can be adopted for applications with attributes that lend themselves to automation, it is often not suitable for many legacy applications. These applications still play a vital role at many enterprises, often serving business-critical workloads. Migrating them to the cloud with the correct controls in place is a necessary step in any enterprise’s cloud journey.
Sourced was engaged at one of its clients to achieve just that. The client’s existing CI/CD pipeline requires application teams to use a standardised blue/green process to deploy and update their applications. This includes performing OS updates, meaning regular re-deployment of the application onto new, fully patched instances. Because of this mandatory and tightly confined approach, patching instances in-place was not yet possible.
The client required a framework that would allow for the deployment of long-lived instances in AWS. The framework needed to provide a more traditional in-place patching capability that was accessible to application teams, with controls in place to allow the governing cloud team to monitor the patch states across the entire AWS environment, ensuring that patch compliance standards are met.
Considerations
In this particular environment, the client houses a multitude of application teams, each with restricted access to separate development and production AWS accounts. Each team has limited read-only access via the AWS console, and must deploy into their account via the previously mentioned CI/CD pipeline. With each team running on their own development and update schedules, the responsibility for Operating System (OS) patching must lie with them. On the other hand, the governing cloud team is responsible for the pipeline, core infrastructure and security controls within the cloud environment.
From these policies or considerations, a responsibility model (pictured below) can be derived.
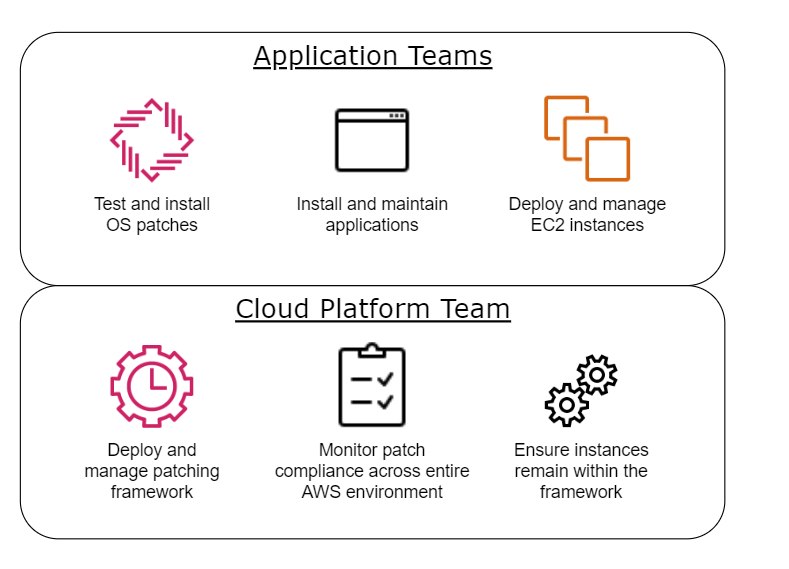
With this in mind, the exact requirements for the solution were as follows:
- Provide a means for application teams to easily patch their instances in-place.
- Enable the ability to scan all long-lived EC2 instances for missing patches across the entire AWS environment.
- Create a reporting framework to allow the cloud team to monitor patch states.
- Establish a method to ensure that all instances in the framework are being monitored.
AWS Patch Manager Framework
The patching framework was implemented using the AWS Systems Manager Patch Manager service. Patch Manager allows for automatic scanning and installation of missing patches on groups of EC2 instances that run a variety of OS releases from Linux to Windows. Once configured, the patching process is automated and handled by the service itself, making patching relatively pain free.
The service was enabled in each account by configuring three main components: patch baselines, patch groups and maintenance windows.
Patch baselines allow you to specify which patches should be installed for a certain OS. They provide a set of filters you can use to automatically approve patches if they fall under a certain set of products, classifications or severities. For this implementation, a patch baseline was deployed to approve all patches for each of the client’s supported operating systems.
Patch groups are used to target a certain set of instances. Adding instances to a patch group simply involves tagging them with the corresponding Patch Grouptag. Systems Manager automatically detects the instance and associates it with the corresponding baseline. By tagging each instance at launch, and ensuring that application teams didn’t have the permissions to remove the tag, we could ensure that all long-lived instances remained assigned to the required patch group.
The final resource required was a maintenance window. Maintenance windows allow you to schedule a periodic scan/install of missing patches against one or more patch groups. We scheduled the window to to run every four hours, and to perform a scan against all of the patch groups in the deployed account using the AWS-RunPatchBaseline document.
With the Patch Manager resources in place, any instance deployed as “long-lived” would now be automatically scanned for missing patches, with the resulting patch states collated by Systems Manager within each account. The next step was to enable the application teams to patch their instances in-place.
Due to the team’s restricted permissions in the AWS console, we needed to provide a method to invoke Systems Manager commands from code and with as few permissions as possible. To achieve this, we developed a set of “helper scripts” for each OS (Bash for Linux and PowerShell for Windows) which, when invoked on an instance, would make the appropriate calls to Systems Manager to invoke a scan and/or install on the instance. To enforce this security, IAM permissions were included with each instance profile to restrict the ability to perform these commands only against the instance from which it was run.
Cross-Account Reporting
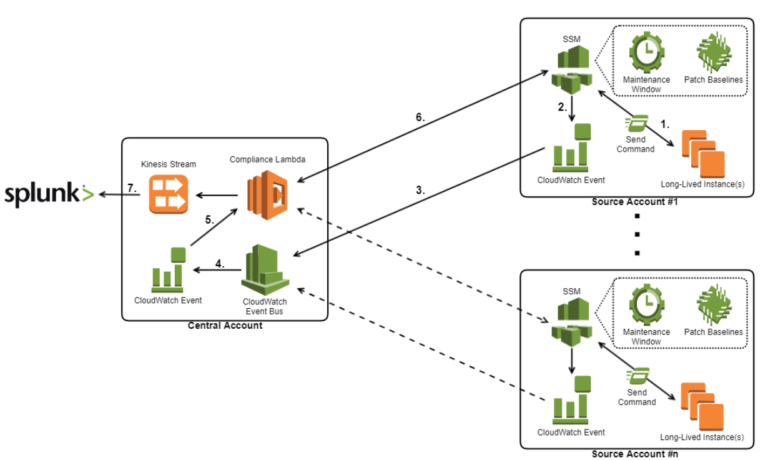
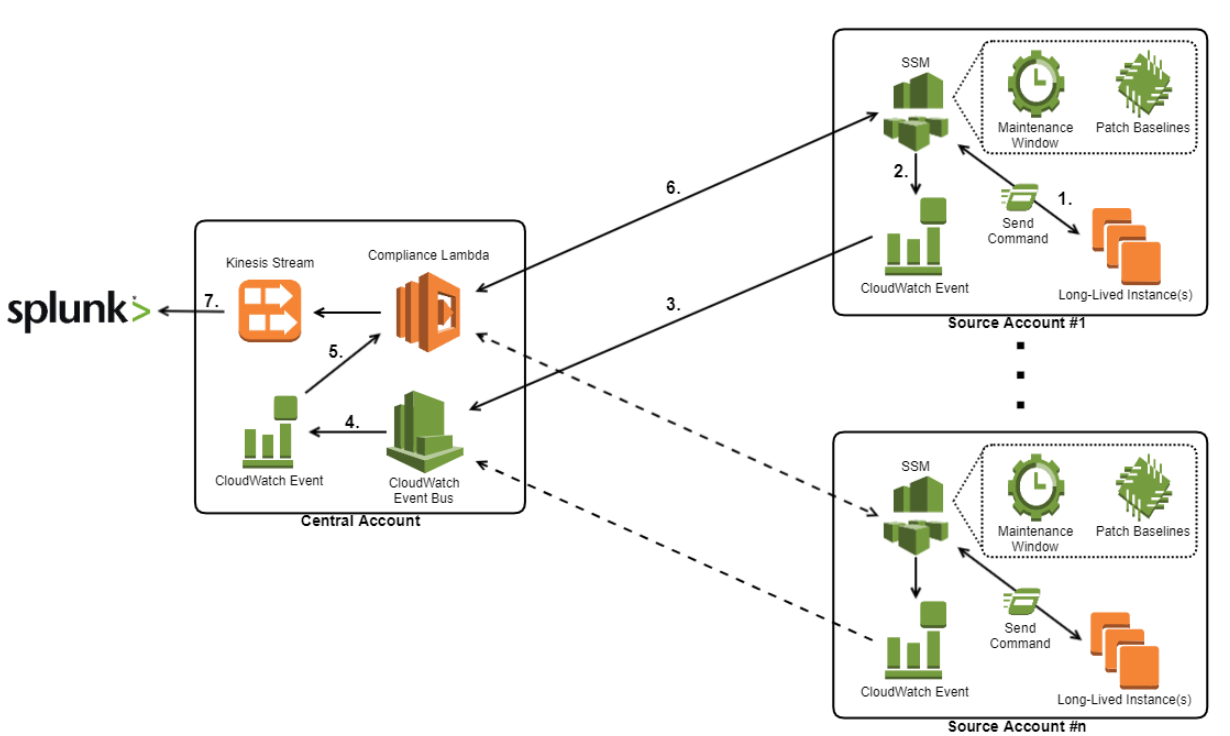
With the patching capability ready to go, the cloud team still required a means to view the patch states across the entire cloud platform for the purpose of monitoring and reporting. Because the patching framework was deployed separately in each account using CloudFormation, we needed a means to centralise the patch compliance data. To achieve this, we made use of a Lambda function, a Kinesis stream, CloudWatch event rules, and CloudWatch event bus, to reactively collect the compliance data from each account whenever a long-lived instance was scanned or patched.
The flow of the design is as follows:
- A command is triggered on an instance, either by Systems Manager Maintenance Window, or by a user running the helper script.
- This will trigger a CloudWatch event rule within the account, which is configured to listen specifically for the AWS-RunPatchBaseline command.
- The command is then sent across a CloudWatch event bus to the central account.
- This in turn triggers a CloudWatch event rule existing in the central account, which is identical to the one within in the source account.
- The CloudWatch event then triggers a Lambda, passing it metadata about the event.
- The Lambda uses the metadata to identify the source account and the instance ID that triggered the event. Using this information, it then assumes into the account, extracts all the necessary compliance data about the specific instance, and transforms it into the required format before inserting it into a Kinesis stream.
- Using the Splunk for AWS app, the data is then retrieved from the Kinesis stream and ingested into Splunk for reporting.
Reporting in Splunk
With the patching and logging framework in place, any instance launched as “long-lived” would now be monitored for their patch states, with the resulting data being collected in Splunk. To visualise this data, a couple of Splunk dashboards were created.
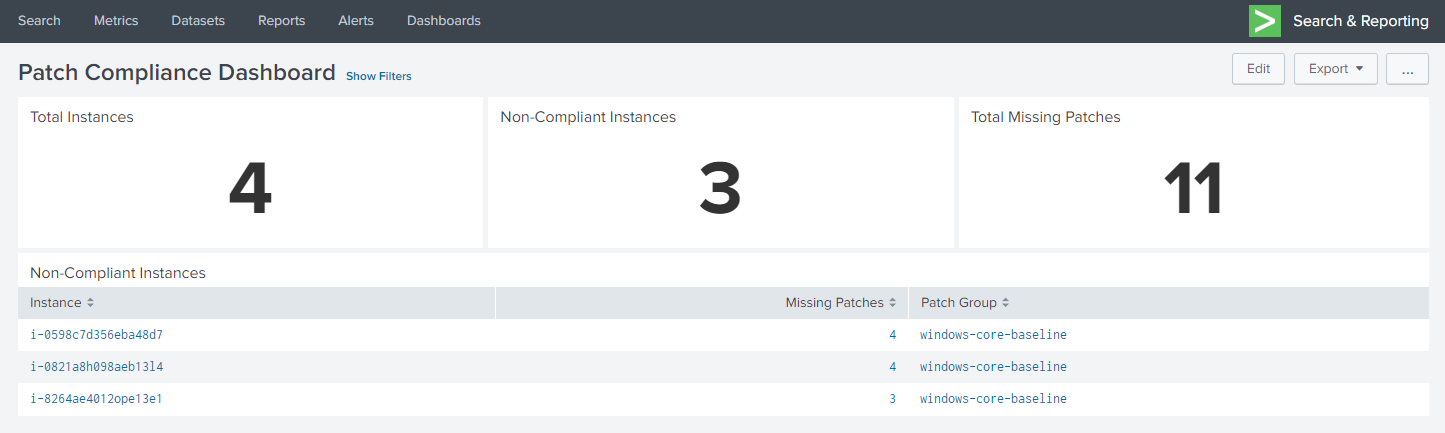
The first dashboard shown below gives a summary of all long-lived instances across the entire cloud environment.
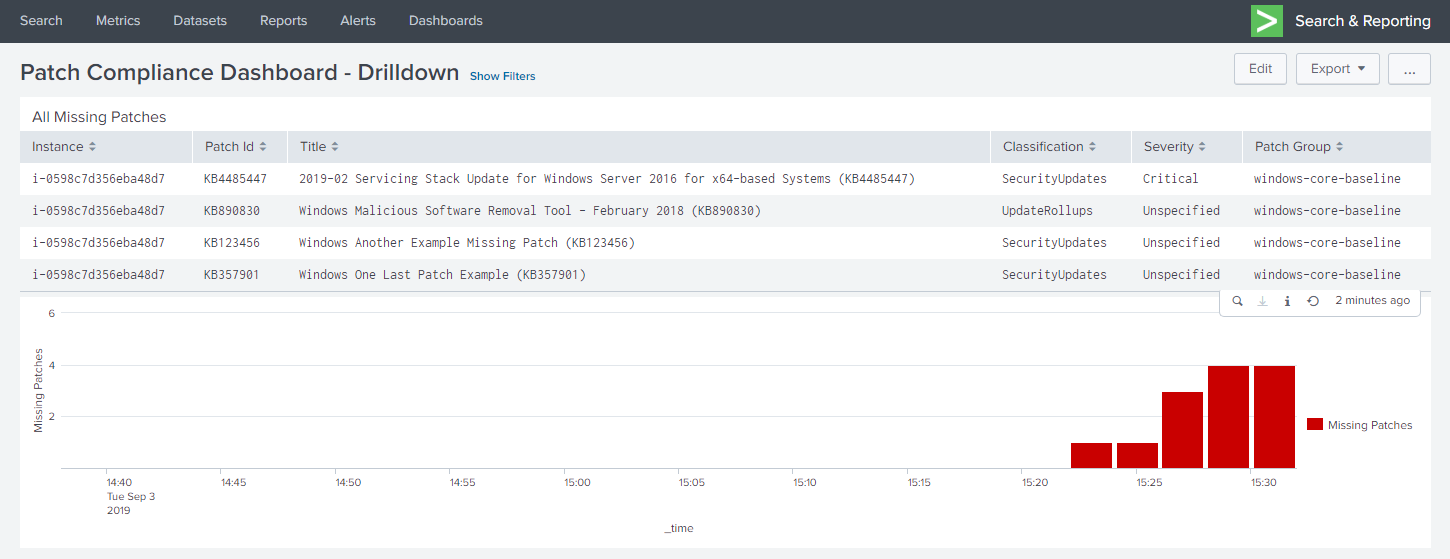
The second dashboard provides a drill-down to view the patch states of a specific instance.
The Lambda function mentioned previously fetches the compliance data from each account transforming it into the following format before Splunk ingests it.
A sample of this data can be seen below:
{
"ComplianceType": "Patch",
"ResourceType": "ManagedInstance",
"ResourceId": "i-21s92jfnasd0923a1",
"Status": "NON_COMPLIANT",
"OverallSeverity": "UNSPECIFIED",
"ExecutionSummary": {
"ExecutionId": "ad378d84-32a9-4cac-a504-5b99490c37d4",
"ExecutionType": "Command"
},
"CompliantSummary": {
"CompliantCount": 15,
"SeveritySummary": {
"CriticalCount": 0,
"HighCount": 0,
"MediumCount": 0,
"LowCount": 0,
"InformationalCount": 0,
"UnspecifiedCount": 15
}
},
"NonCompliantSummary": {
"NonCompliantCount": 2,
"SeveritySummary": {
"CriticalCount": 0,
"HighCount": 0,
"MediumCount": 0,
"LowCount": 0,
"InformationalCount": 0,
"UnspecifiedCount": 2
}
},
"MissingPatches": [
{
"Id": "KB4485447",
"Title": "2019-02 Servicing Stack Update for Windows Server 2016 for x64-based Systems (KB4485447)",
"Severity": "UNSPECIFIED",
"Details": {
"Classification": "SecurityUpdates",
"PatchBaselineId": "pb-0c67a82f35616e86e",
"PatchGroup": "windows-core-baseline",
"PatchSeverity": "Critical",
"PatchState": "Missing"
}
},
{
"Id": "KB890830",
"Title": "Windows Malicious Software Removal Tool - February 2018 (KB890830)",
"Severity": "UNSPECIFIED",
"Details": {
"Classification": "UpdateRollups",
"PatchBaselineId": "pb-0c67a82f35616e86e",
"PatchGroup": "windows-core-baseline",
"PatchSeverity": "Unspecified",
"PatchState": "Missing"
}
}
],
"Account": "redacted",
"Name": "redacted"
}Challenges
There were a few challenges encountered when implementing the framework.
Having the application teams perform their own OS patches gives them time to test in their development environment before applying the updates to production. However, in the situation where an update causes an application to break, the teams required a way to omit certain patches. The idea of allowing application teams to create their own custom baselines was considered. However, due to the fact that Patch Manager associates baselines using instance tags, the application teams would also need permissions to alter those tags, which wasn’t a viable option for the client.
The solution was to allow users to provide an override list containing the IDs of patches they wanted to omit, which is passed to Systems Manager when running an install patch command. Unfortunately, Systems Manager only allows you to provide a list of patches that you want to install, therefore the helper script was designed to first obtain a list of all missing patches on the instance, remove the patches from the list that was provided by the user, and then send the resulting list to Systems Manager to perform the install command.
Another problem was ensuring that certain services and configuration files associated with Systems Manager were present and maintained on the long-lived instances.
For Systems Manager to communicate with an instance, the Systems Manager agent needs to be running. Because each application team has Administrator or root access to any instance they deploy, the cloud platform team needed a method to ensure that the agents were continuously running on all long-lived instances. This was to ensure that they could monitor the instance’s patch state, and to ensure that the helper scripts would function correctly when they were invoked.
To address this challenge, we opted to deploy a Puppet Master into the environment using the AWS Opsworks for Puppet Enterprise service to manage the configuration management requirements of the long-lived instances. The deployment and integration of this service in the client’s environment is detailed in a previous blog post “Pulling Puppet’s Strings with AWS OpsWorks CM“, and the data produced by this service when aggregated with the patch compliance data produced by this capability, enabled the client to have high confidence in the compliance state of their environment at both a configuration management and patching level.
Conclusion
By using Systems Manager Patch Manager service, the patching process is seamless and entirely abstracted, allowing application teams to patch their instances in-place without the need for deep knowledge on the subject. By using custom scripts to interact with the service, teams can test and deploy updates on their own schedule, relieving pressure on centralised IT functions. And finally, the automated scanning, along with the reporting framework, provides the governing cloud team a complete view of the state of patch compliance across the entire environment.

Tyler Matheson is an associate consultant based in Sydney, Australia.



{kind=link}